
Base de datos a utilizar
Obteniendo los niveles de pobreza de Costa Rica
Sobre la medición de pobreza en Costa Rica
La medición de la pobreza en Costa Rica es llevada a cabo por el Instituto Nacional de Estadísticas y Censos (INEC), haciendo uso de los datos recopilados a través de la Encuesta Nacional de Hogares. La actual encuesta de hogares recopila información que permite la estimación de la pobreza monetaria, así como de la pobreza multidimensional1. Para la estimación de la pobreza monetaria o económica (en adelante pobreza) se utiliza el método de línea de pobreza teniendo el ingreso como medida de bienestar2. Además, se definen dos umbrales de comparación o líneas de pobreza: la línea de pobreza extrema y la línea de pobreza (general), dichas líneas son diferenciadas por área de residencia (INEC, 2018).
La línea de pobreza extrema “corresponde al costo per cápita mensual de la Canasta Básica Alimentaria (CBA)” (INEC, 2018 página 20). La Canasta Básica Alimentaria (CBA) representa el consumo calórico promedio mínimo diario por persona, estando compuesta por alimentos que fueron seleccionados en función de su aporte calórico y frecuencia de consumo. Las estimaciones del costo de dicha canasta realizados por INEC (2018) para junio de 2018 ascienden a 49,999 colones para el área urbana y 41,483 colones para el área rural, estos montos corresponden a la línea de pobreza extrema.
Por su parte, el INEC (2018) define la línea de pobreza (general) como “el monto mínimo que un hogar requiere para satisfacer sus necesidades básicas alimentarias y no alimentarias”, dicho monto se estima considerando el costo de la Canasta Básica Alimentaria (CBA) más un monto estimado del costo de satisfacer las necesidades no alimentarias. De este modo, la línea de pobreza se estimó para junio de 2018 en 110,047 colones para el área urbana y 84,535 colones para el área rural.
Disponibilidad de bases de datos
El INEC ha recolectado datos sobre las condiciones de vida de los costarricenses mediante un programa permanente que inició en 1976, desde entonces se han llevado a cabo dos actualizaciones conceptuales y metodológicas de la encuesta y las mediciones de pobreza, una en 1987 y otra en 2010. A partir de 2010 se realiza anualmente la Encuesta Nacional de Hogares (en adelante ENAHO), la cual es una encuesta de hogares de propósitos múltiples enfocada en indicadores del bienestar de la población que aborda diferentes tópicos como ingreso, vivienda, empleo, educación, seguridad social, entre otras; dicha encuesta tiene representatividad a nivel nacional, por áreas de residencia y regiones. Las bases de datos se encuentran disponibles en la página web del INEC en el apartado de “Bases de datos y documentación” y luego “Programa acelerado de datos”. La última ENAHO disponible corresponde a 20183. Toda la información de la encuesta ya está unida en una sola base de datos con registros por persona4.
Obteniendo indicadores de pobreza
Para realizar las estimaciones se debe declarar el diseño de la muestra, el cual corresponde a un diseño estratificado, el estrato sería la región (REGION, en la base de datos); la ponderación (peso) corresponde a la variable FACTOR y la unidad de muestreo es la unidad primaria de muestreo UPM5.
Incidencia de la pobreza
En función de las líneas de pobreza se identifican 3 niveles de pobreza:
1) La pobreza extrema, en la cual se ubican los hogares cuyo ingreso per cápita es “igual o inferior” a la línea de pobreza extrema.
2) La pobreza no extrema, en la que se encuentran aquellos hogares que tienen un ingreso per cápita mayor a línea de pobreza extrema, pero “menor o igual” a línea de pobreza.
3) No pobre, si el hogar tiene un ingreso per cápita mayor a la línea de pobreza.
Cabe señalar que el INEC (2018) considera pobres a los hogares cuyo ingreso per cápita es igual a la línea de pobreza (extrema o general), esto no siempre es así, en otros países se consideran pobres a los hogares cuyo ingreso o consumo per cápita es menor a la línea de pobreza (extrema o general).
Para obtener la incidencia de la pobreza o también denominado índice de recuento según el método del índice FGT (Foster, Greer y Thorbeke), que es el método utilizado para el análisis de la pobreza monetaria; se procede a estimar la proporción de personas (Programación 1) y/o hogares (Programación 2A y 2B) que tienen un ingreso per cápita menor o igual a las líneas de pobreza definidas.
Programación 1: Incidencia de la pobreza (proporción de personas)
svy linearized: proportion np
Tabla 1: Incidencia de la pobreza (proporción de personas)
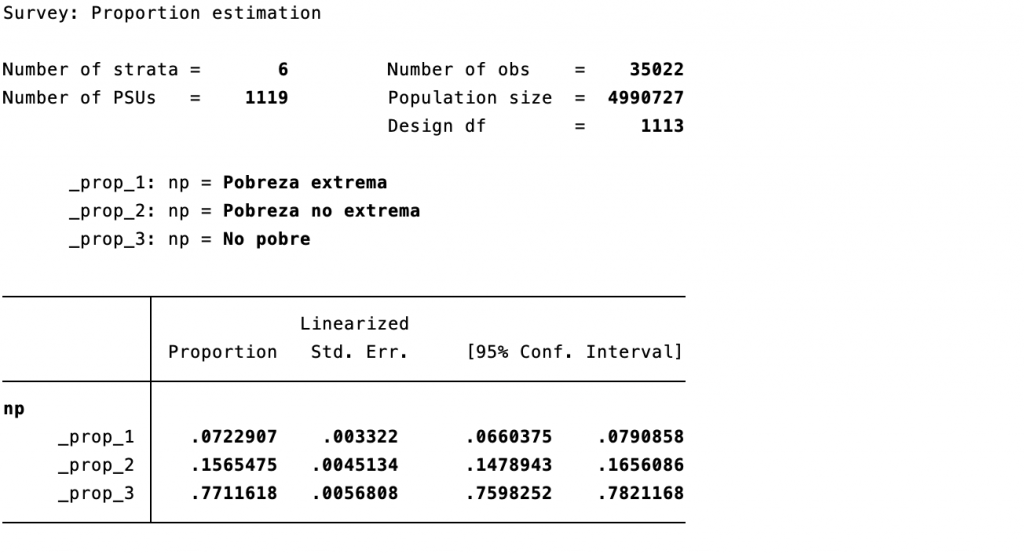
Debido a que la base de datos está estructurada por personas (esta es la población de estudio), la proporción que obtenemos de la Programación 1 corresponde a personas, de este modo se obtiene que para el año 2018 el 7.2% de la población costarricense vivía en condición de pobreza extrema, 15.6% se encontraba en pobreza no extrema, mientras que 77.1% de la población ese año no era pobre.
Si quisiéramos estimar la incidencia de la pobreza a nivel de hogares se debe hacer una pequeña modificación en la Programación 1 (ver Programación 2A y 2B) para acotar la estimación a una población diferente, en este caso a hogares. Esta delimitación consiste en dejar una observación de una persona que represente al hogar6, lo cual puede lograrse usando la variable Parentesco con el jefe/a de hogar (A3 en la base), la nueva población (sub población, por eso en Programación 2B se usa el comando subpop) sobre la que se calcularía la proporción de pobres sería para todos los jefes de hogar, ya que la cantidad de jefes de hogar es igual a la cantidad de hogares. Debido a que el código de parentesco del jefe/a e hogar es 1, la sub población se limita a ese criterio. Para especificar esa sub población en la estimación, puede usarse la Programación 2A o 2B, con ambas se obtiene el mismo resultado.
Programación 2A: Incidencia de la pobreza (proporción de hogares)
svy linearized: proportion np if A3==1
Programación 2B: Incidencia de la pobreza (proporción de hogares)
svy linearized, subpop (if A3==1): proportion np
Tabla 2A: Incidencia de la pobreza (proporción de hogares)

Tabla 2B: Incidencia de la pobreza (proporción de hogares)
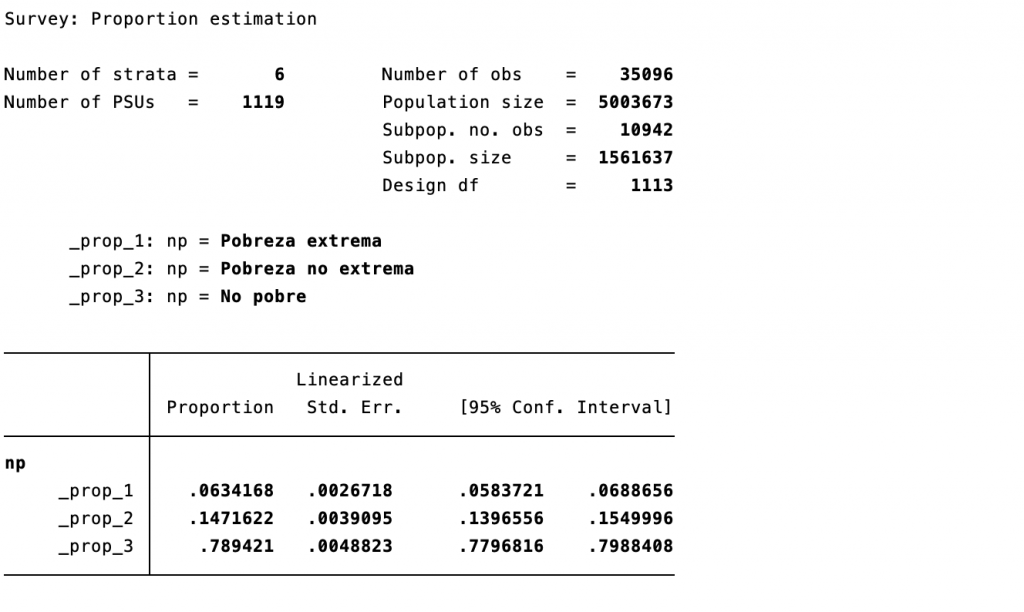
De este modo, puede concluirse que para el año 2018 el 21.1% de los hogares costarricenses se encontraban en condición de pobreza total, siendo el 6.3% de los hogares afectados por la pobreza extrema; mientras que 78.9% de los hogares no eran pobres. Estos resultados coinciden con los presentados en el Informe de resultados generales de ENAHO 20187.
Tamaño de los hogares por condición de pobreza
Debido a que la condición de pobreza de los hogares y las personas se estima a partir del ingreso per cápita, es de esperarse que el tamaño del hogar (cantidad de personas que componen el mismo) esté relacionado con la situación de pobreza. Para analizar esta relación debe estimarse el promedio de personas que viven en cada hogar, esta información está disponible en la variable TamHog que incluye un conteo de los miembros de hogar.
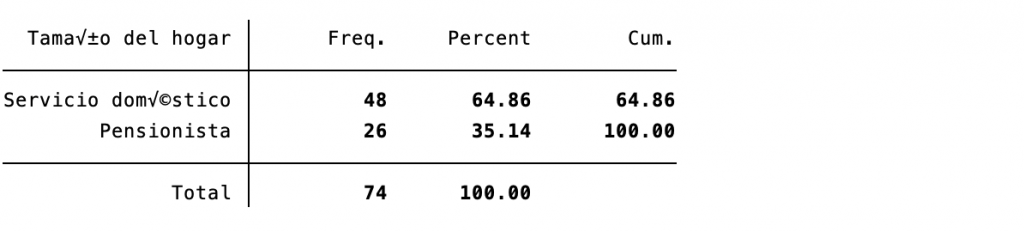
El primer paso para realizar esta estimación es conocer los valores de la variable TamHog, para esto se ejecuta la Programación 3A, en los resultados de la misma (ver Tabla 3A) se observa que la cantidad máxima de miembros por hogar es 19 personas y que hay dos valores que están etiquetados como servicio doméstico y pensionistas, debido a que estas personas no son miembros del hogar8. Para conocer la cantidad de personas dentro de estas categorías se ejecuta la Programación 3B y se obtiene (ver Tabla 3B) que los valores asignados a estas personas son 98 y 99 respectivamente.
Programación 3A: Tabulación de tamaño del hogar (cantidad de miembros)
tab TamHog
Programación 3B: Tabulación de tamaño del hogar (cantidad de miembros) para personas no miembros de hogar
lab list TamHog
tab TamHog if TamHog>=97
Tabla 3A: Tabulación de tamaño del hogar (cantidad de miembros)

Tabla 3B: Tabulación de tamaño del hogar (cantidad de miembros) para personas no miembros de hogar
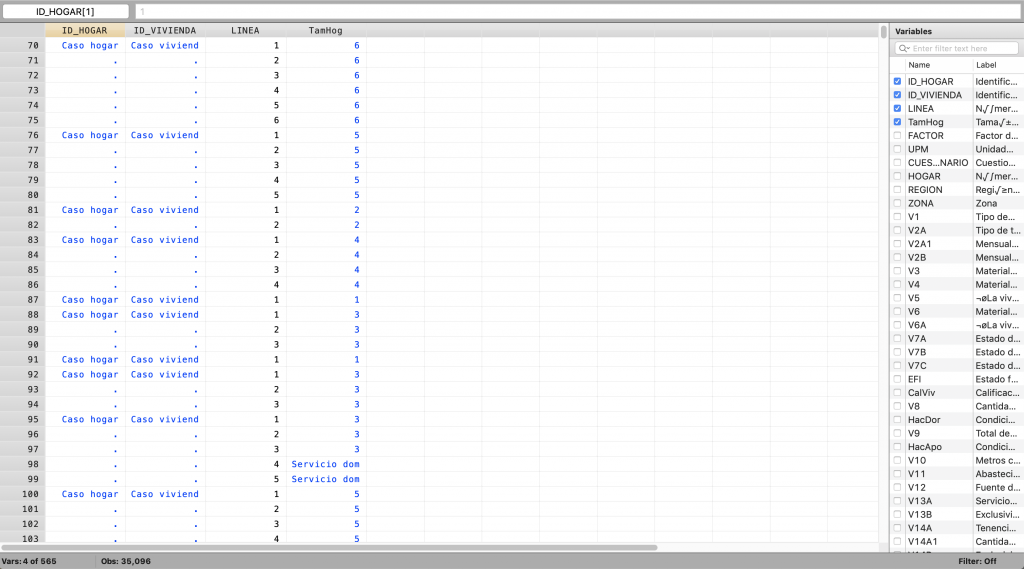
Debido a que la estimación del promedio de personas es por hogar, la estimación debe limitarse a los jefes de hogar. Para verificar que los valores 98 y 99 no están incluidos en la cantidad de miembros por hogar en TamHog, se ejecuta la Programación 3C en la cual se pide mostrar (br o browse) los datos de identificación del hogar, de las personas, y los valores de TamHog. Los resultados de este comando (ver Tab 3C) indican que estas personas no fueron incluidas en el conteo de miembros de hogar.
Programación 3C: Verificación de no miembros de hogar dentro de conteo
br ID_HOGAR ID_VIVIENDA LINEA TamHog
Imagen 3C: Verificación de no miembros de hogar dentro de conteo. Ver que los registros del 95 a 99, corresponde a personas que viven en la misma vivienda, sin embargo, solamente los primeros tres (95, 96 y 97) son miembros del hogar.
Imagen C3: Verificación de no miembros de hogar dentro de conteo
De este modo se procede a realizar la estimación del tamaño promedio de los hogares costarricenses a nivel nacional, siguiendo la Programación 4A. Para obtener el tamaño promedio de los hogares por condición de pobreza se ejecuta la Programación 4B, a fin de obtener resultados comparables con los reportados en el informe de resultados generales de la ENAHO 2018, se ejecuta la Programación 4C para conocer el tamaño promedio de los hogares pobres totales (np diferente de 3).
Programación 4A: Cantidad promedio de personas por hogar a nivel nacional
svy linearized, subpop (if A3==1): mean TamHog
Programación 4B: Cantidad promedio de personas por hogar por condición de pobreza
svy linearized, subpop (if A3==1): mean TamHog, over (np)
Programación 4C: Cantidad promedio de personas por hogar en hogares pobres generales (incluye pobres extremos y pobres no extremos)
svy linearized, subpop (if A3==1): mean TamHog if np!=3
Los resultados de las programaciones anteriores indican que para el año 2018 los hogares costarricenses estaban conformados en promedio por 3.20 personas (ver Tabla 4A), y que el tamaño de los hogares tiene una relación con la condición de pobreza, para 2018 los hogares pobres extremos tenían en promedio 3.64 miembros, los hogares pobres no extremos 3.40 miembros (ver Tabla 4B). De manera agregada, los hogares pobres en promedio están conformados por 3.47 personas, mientras que los hogares no pobres por 3.12 personas9.
El tamaño promedio de los hogares por condición de pobreza es estadísticamente significativo y diferente entre ellos, debido a que el error estándar es menor al 0.05 (solo para los pobres extremos es mayor, pero es significativo al 10%, es menor a 0.1) y a que la media de un grupo está fuera del intervalo de confianza de los otros grupos (condiciones de pobreza). Por lo cual, se puede afirmar que los hogares pobres tienden a ser más grandes, eso implica una mayor población en condición vulnerable.
Tabla 4A: Cantidad promedio de personas por hogar a nivel nacional
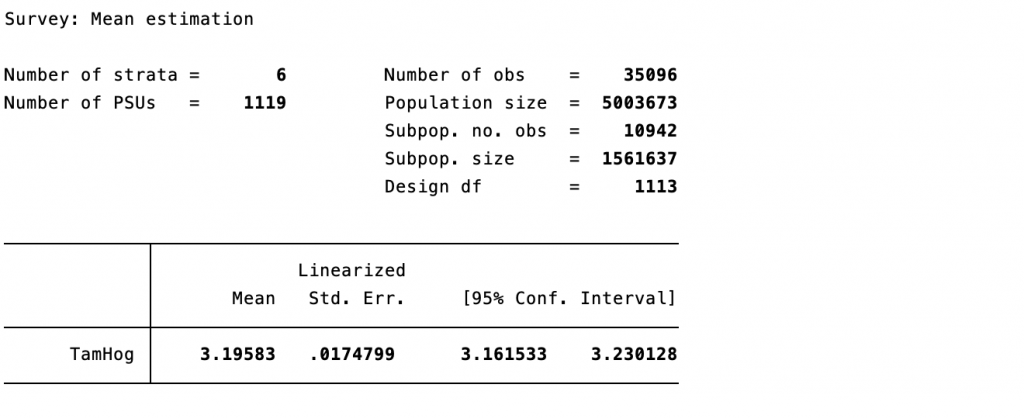
Tabla 4B: Cantidad promedio de personas por hogar por condición de pobreza

Tabla 4C: Cantidad promedio de personas por hogar en hogares pobres generales (incluye pobres extremos y pobres no extremos)
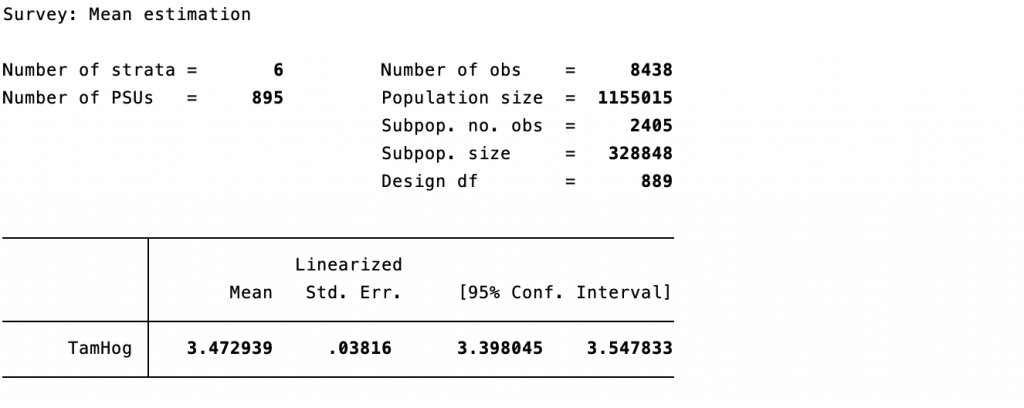
Cantidad promedio de personas adultas mayores por hogar
Los adultos mayores son un grupo vulnerable de población, debido al momento del ciclo de vida en que se encuentran requieren de servicios de cuidado y salud, y ya no pueden realizar trabajos remunerados con facilidad, quienes lo hacen generalmente lo consiguen de forma precaria como un medio de subsistencia; de modo que ser pobre en esta etapa de la vida implica una vulnerabilidad mayor a la experimentada durante la vida adulta.
A fin de vislumbrar si existe una concentración de este grupo poblacional por condición de pobreza, se puede estimar la cantidad promedio de adultos mayores en los hogares por condición de pobreza, para esto primero se debe identificar a las personas que son adultos mayores. Según INEC (20108) se consideran adultos mayores a todas las personas de 65 años de edad y más, además estas personas deben ser miembros del hogar. De este modo se verifica la cantidad total de personas y de observaciones que cumplen con estos criterios ejecutando la programación 5A, luego se genera la variable de identificación aplicando la programación 5B.
Programación 5A: Total de observaciones que cumplen los criterios de adulto mayor
sum A5 if A5>=65 & TamHog<97
Programación 5B: Crear variable identificación de adultos mayores miembros de hogar
capture drop admayor
gen admayor=.
replace admayor=0 if TamHog<97
replace admayor=1 if A5>=65 & TamHog<97
labe var admayor "Adulto mayor"
label define admayor 1 "Si" 0 "No", replace
label values admayor admayor
tab admayor
Tabla 5A: Total de observaciones que cumplen los criterios de adulto mayor

Tabla 5B: Tabulación de variable de identificación de adultos mayores miembros de hogar

Como se observa en las Tablas 5A y 5B la creación de la variable de identificación coincide con la cantidad de observaciones de personas que son miembros de hogar y tiene 65 o más años de edad.
Para crear la variable de conteo de las personas adultas mayores en cada hogar se necesita una variable de identificación única por hogar, debido a que esta variable no existe en la base de datos se procede a crearla a partir de las variables de identificación de los hogares, estas son: UPM, ZONA, REGION, CUESTIONARIO y HOGAR. La variable de identificación para que sea única debe contener todos los códigos anteriores, pero como están en formato de número tienen diferente cantidad de dígitos y al unirlos ocasionaría problemas, de este modo se debe explorar la cantidad máxima de dígitos para cada variable (ver Programación 5C), de modo que se pueda homologar la cantidad de dígitos de cada variable.
Programación 5C: Explorar valores de variables de identificación
sum UPM ZONA REGION CUESTIONARIO HOGAR LINEA
Tabla 5C: Explorar valores de variables de identificación
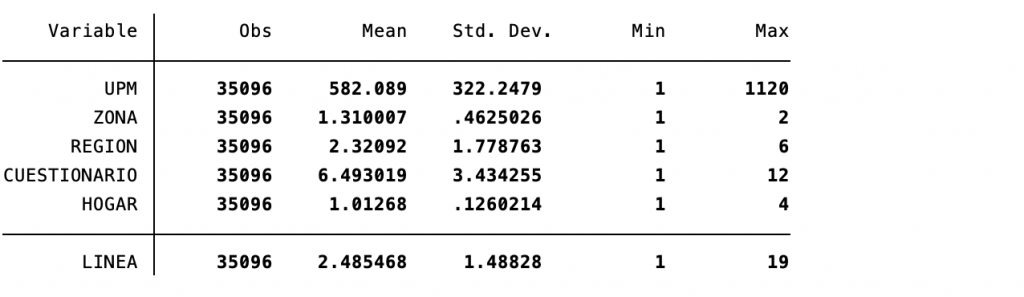
Como se observa en la Tabla 5C las variables UPM, CUESTIONARIO y LINEA necesitan ajustarse a un código de igual cantidad de dígitos. En el caso de UPM la variable nueva debe contener 4 dígitos, para CUESTIONARIO y LINEA, 2 dígitos. Dicho ajuste requiere la creación de una nueva variable que tenga ese formato, la cual se crea a partir de la unión (concatenación) de variables intermedias para cada grupo de datos con una cantidad específica de dígitos originales. De este modo, la primera variable que se crea es una variable de ceros la cual se irá uniendo con los valores de las variables de identificación.
Programación 5D: Creación de variable cero
capture drop cero
gen cero=0
sum cero
Tabla 5D: Resultado de creación de variable cero

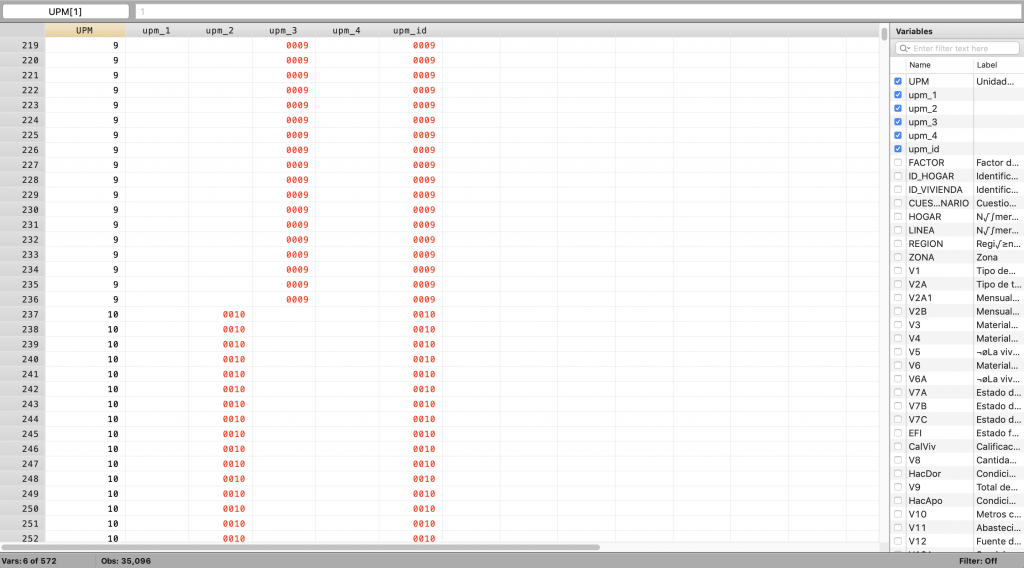
Para crear el nuevo código UPM homologado a la misma cantidad de dígitos, se crean 4 variables intermedias, las cuales luego se unen para crear una sola variable estandarizada. Este proceso se presenta en la Programación 5E. Nótese que se usa el comando egen para crear las nuevas variables porque se necesita hacer una función u operación para generar esa variable, en este caso es concatenar la variable cero con UPM en función de ciertos criterios que están definidos por la cantidad de dígitos. De este modo, se agrega solo un cero para los valores UPM de 3 dígitos (entre 99 y 1000), se agregan 2 ceros para los valores de UPM de 2 dígitos (entre 10 y 100) y se agregan 3 ceros para los valores de UPM de un dígito (menores a 10).
Programación 5E: Creación de variables de igual cantidad de dígitos para UPM
capture drop upm_1
egen upm_1=concat(cero UPM) if UPM<1000&UPM>99
capture drop upm_2
egen upm_2=concat(cero cero UPM) if UPM<100&UPM>=10
capture drop upm_3
egen upm_3=concat(cero cero cero UPM) if UPM<10
capture drop upm_4
egen upm_4=concat(UPM) if UPM>=1000
capture drop upm_id
egen upm_id=concat(upm_1 upm_2 upm_3 upm_4)
br UPM upm_1 upm_2 upm_3 upm_4 upm_id
Imagen 5E: Creación de variables de igual cantidad de dígitos para UPM
La misma dinámica se sigue para las variables CUESTIONARIO y LINEA para que tengan valores con la misma cantidad de dígitos. El procedimiento se muestra en la Programación 5F y Programación 5G, respectivamente.
Programación 5F: Creación de variables de igual cantidad de dígitos para CUESTIONARIO
capture drop cuestionario_1
egen cuestionario_1=concat(cero CUESTIONARIO) if CUESTIONARIO<10
capture drop cuestionario_2
egen cuestionario_2=concat(CUESTIONARIO) if CUESTIONARIO>=10
capture drop cuestionario_id
egen cuestionario_id=concat(cuestionario_1 cuestionario_2)
br CUESTIONARIO cuestionario_1 cuestionario_2 cuestionario_id
Imagen 5F: Creación de variables de igual cantidad de dígitos para CUESTIONARIO
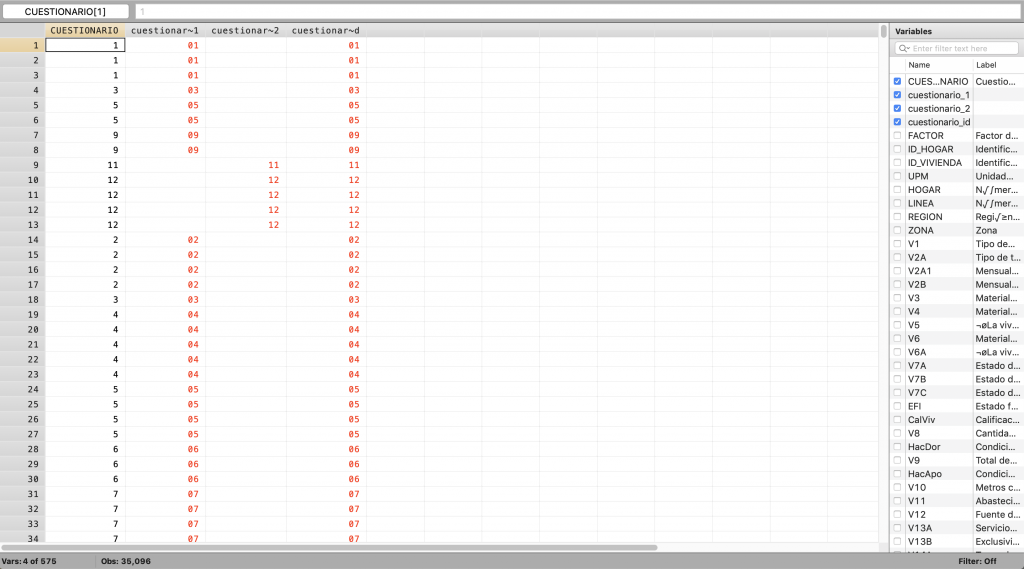
Programación 5G: Creación de variables de igual cantidad de dígitos para LINEA
capture drop linea_1
egen linea_1=concat(cero LINEA) if LINEA<10
capture drop linea_2
egen linea_2=concat(LINEA) if LINEA>=10
capture drop linea_id
egen linea_id=concat(linea_1 linea_2)
br LINEA linea_1 linea_2 linea_id
Imagen 5G: Creación de variables de igual cantidad de dígitos para LINEA
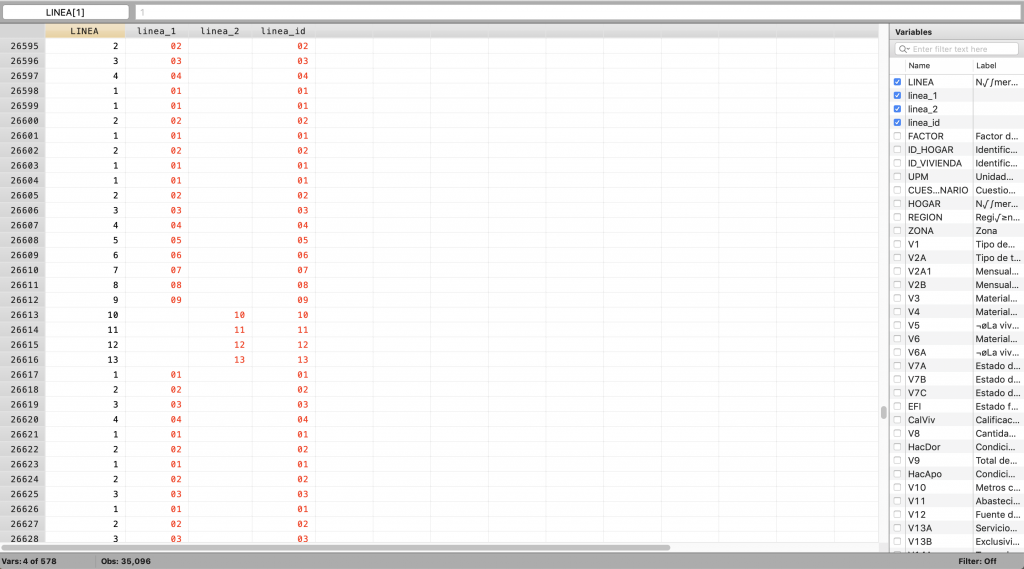
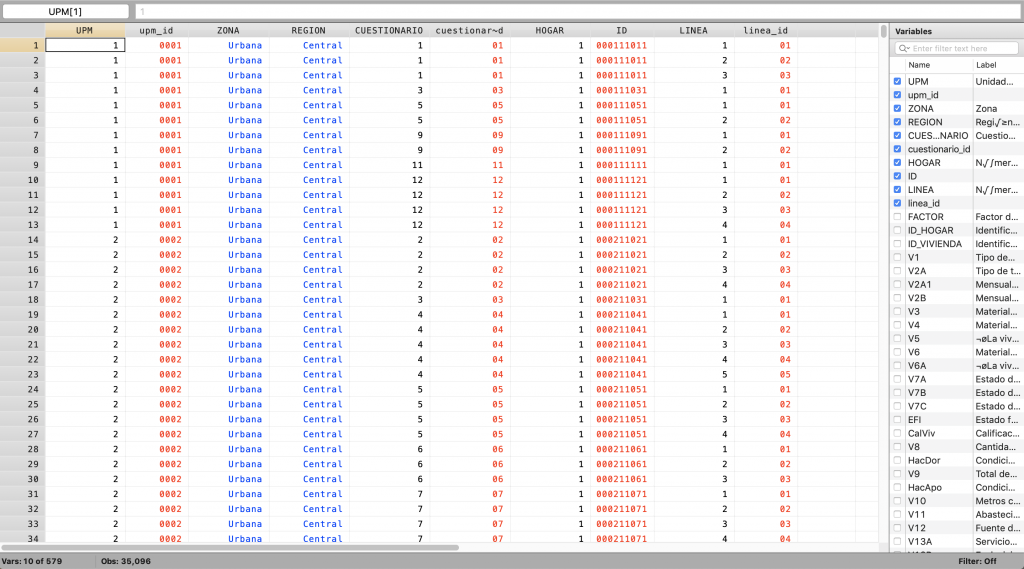
Una vez que se han generado las variables de los nuevos códigos UPM, CUESTIONARIO y LÍNEAse procede a generar una variable de identificación única de los hogares, de igual manera que las variables anteriores, esta variable consiste de la unión de todos los códigos de identificación de hogar, por lo cual se usa el mismo comando egen y la misma función concat() (ver Programación 5H).
Programación 5H: Creación de identificador único por hogar
capture drop ID
egen ID= concat(upm_id ZONA REGION cuestionario_id HOGAR)
br UPM upm_id ZONA REGION CUESTIONARIO cuestionario_id HOGAR ID LINEA linea_id
Imagen 5H: Creación identificador único por hogar
Ahora que se ha creado una variable de identificación única por hogares se procede a verificar que esta variable tiene valores únicos para cada hogar. Para esto se usan los comandos presentados en la Programación 5I. Note que para usar el comando quietly by necesita antes haber ordenado los datos por las mismas variables que se agrupará la estimación o se creará la nueva variable, quietly by indica que se generará un valor por grupo, ese grupo está definido después del comando quietly by . Por su parte, la expresión cond(_N==1,0,_n) indica que se generará un valor que va de 0 a n, y ese valor representa la cantidad de veces que hay una combinación de valores “ID linea_id” repetidos. En la Tabla 5I se observa que la variable de identificación única fue creada correctamente pues hay “0” valores duplicados.
Programación 5I: Verificación de duplicados en variable de identificación
sort ID linea_id
capture drop dup
quietly by ID linea_id: gen dup = cond(_N==1,0,_n)
tab dup
Tabla 5I: Verificación de duplicados en variable de identificación

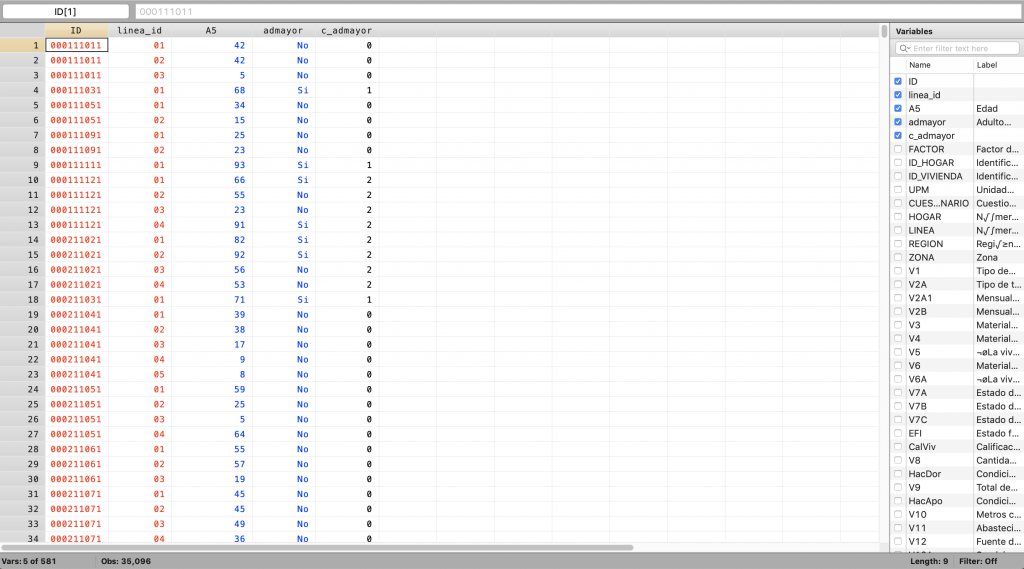
Ahora se puede crear la variable de conteo de adultos mayores por hogar, para este fin se también se usa el comando quietly by, esta vez se quiere crear una variable para cada grupo de ID, pues cada valor de ID identifica un hogar. Además se usa el comando egen debido a que la variable a generar es una estimación o función de los datos, esta vez queremos que totalice la variable admayor dentro de cada hogar (ver Programación 5J).
Programación 5J: Cantidad de adultos mayores por hogar
capture drop c_admayor
sort ID linea_id
quietly by ID: egen c_admayor = total(admayor)
tab c_admayor
br ID linea_id A5 admayor c_admayor
Tabla 5J: Cantidad de adultos mayores por hogar

Imagen 5J: Cantidad de adultos mayores por hogar
Por último, procedemos a estimar la cantidad promedio de adultos mayores por hogar, primero realizamos esta estimación a nivel nacional, luego por condición de pobreza y luego solamente para los pobres totales (np diferente de 3), el procedimiento en Stata se presenta en la Programación 6A, 6B y 6C respectivamente.
Programación 6A: Cantidad promedio de adultos mayores por hogar
svy linearized, subpop (if A3==1): mean c_admayor
Programación 6B: Cantidad promedio de adultos mayores por hogar por condición de pobreza
svy linearized, subpop (if A3==1): mean c_admayor, over(np)
Programación 6C: Cantidad promedio de adultos mayores por hogar en hogares pobres
svy linearized, subpop (if A3==1): mean c_admayor if np!=3
De acuerdo a los resultados de las Tablas 6A, 6B y 6C podemos concluir que en promedio hay menos de una persona adulta mayor por hogar, es decir que no en todos los hogares hay personas mayores, a nivel nacional para 2018 en cada hogar en promedio había 0.35 personas de 65 años o más. No obstante, se observa un promedio de personas adultas mayores levente mayor en los hogares pobres (0.40 personas) que en los hogares no pobres (0.34 personas) y la presencia promedio de adultos mayores es aún mayor en los hogares pobres extremos (0.45 personas), todos estos promedios son estadísticamente significativos y también son estadísticamente diferentes entre ellos.
Tabla 6A: Cantidad promedio de adultos mayores por hogar

Tabla 6B: Cantidad promedio de adultos mayores por hogar por condición de pobreza
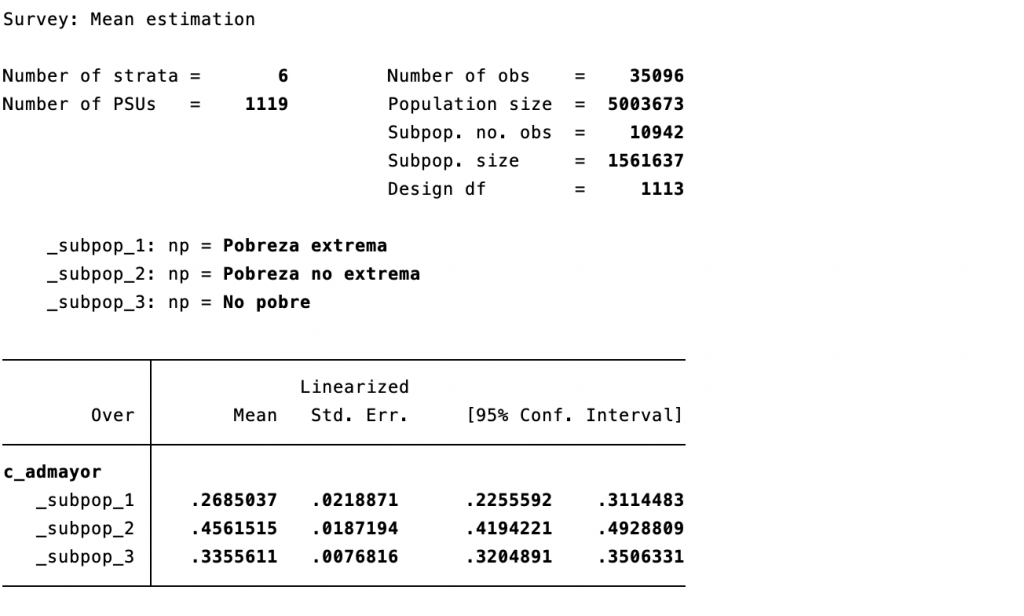
Tabla 6C: Cantidad promedio de adultos mayores por hogar en hogares pobres

Tarea
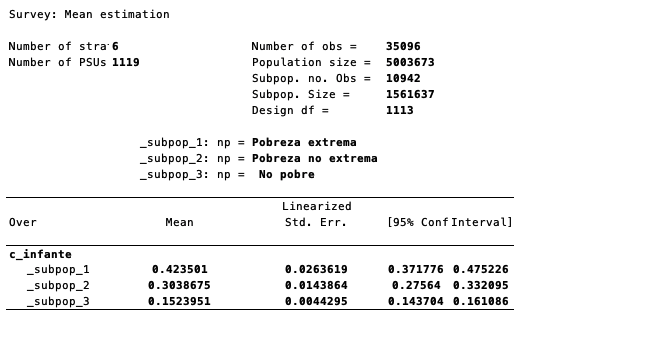
Utilizando los comandos presentados en este documento, realiza un conteo de los infantes en cada hogar y estima la cantidad promedio de infantes a nivel nacional y por condición de pobreza.
Nota: Se consideran infantes a los niños con edades desde los 0 hasta los 4 años.
Puedes verificar tus estimaciones si coinciden con las siguientes:
Tabla 7A: Cantidad promedio de infantes por hogar

Tabla 7B: Cantidad promedio de infantes por hogar por condición de pobreza
Te invitamos a continuar la serie de tutoriales. Puedes ver la ruta de aprendizaje recomendada en: https://escueladedatos.online/serie-de-tutoriales-conociendo-los-indicadores-de-pobreza-de-centroamerica/
Notas
1 La pobreza multidimensional es una definición teórica y metodológica de la pobreza como un estado de privación en diferentes áreas de la vida determinantes para el funcionamiento de los individuos en la sociedad y para su desarrollo como seres humanos, no solo en el acceso a ingreso/consumo (para mayor información al respecto visitar https://ophi.org.uk/research/multidimensional-poverty/). En Costa Rica se ha adaptado la metodología global de pobreza multidimensional con el acompañamiento técnico de la Iniciativa para la Pobreza y Desarrollo Humano de la Universidad de Oxford (OPHI por sus siglas en inglés) y a partir de 2010 se estima el índice de pobreza multidimensional nacional (IPM).
2 El método de línea de pobreza puede ser aplicado haciendo uso del consumo o del ingreso como medida de bienestar, es decir como indicador de la (in)capacidad del hogar o la persona de satisfacer un nivel mínimo de necesidades básicas.
3 Para ver detalles sobre la encuesta y acceder a los datos ver: http://sistemas.inec.cr/pad4/index.php/catalog/203 Cabe mencionar que para descargar los datos se debe crear una cuenta en la página web de INEC en el link anterior.
4 La base de datos no se encuentra disponible en formato de datos de Stata (dta) sino en formato de datos de SPSS (sav) por lo que antes de usar los datos en Stata se deben haber exportado usando SPSS, Tableau u otro programa estadístico disponible que permita hacer la conversión de datos (puede exportarse a Excel primero, luego Stata puede importar datos desde Excel).
5 Para mayores detalles al respecto ver “Declarando el diseño muestral” en Recursos complementarios. Link: https://escueladedatos.online/una-mirada-a-los-indicadores-de-pobreza-en-centroamerica-utilizando-stata-nicaragua/
6 Esto no es problema ya que la información de ingreso se construye por hogar y luego se repite para cada persona miembro de ese hogar.
7 Ver página 39 de Informe de resultados generales ENAHO 2018 en: http://inec.cr/sites/default/files/documetos-biblioteca-virtual/enaho-2018.pdf
8 En las encuestas de medición del nivel de vida y estimación de la pobreza se consideran miembros de hogar las personas que comen y duermen habitualmente en la vivienda al menos 3 de los últimos 12 meses, pero se excluye a los trabajadores domésticos y pensionistas (personas que paga por comer y dormir en la vivienda), ya que sus ingresos no aportan al hogar en el cual habitan y sus gastos son servicios pagados por el hogar, en el caso del servicio doméstico, o son ingresos percibidos por el hogar, en el caso de los pensionistas.
Trackbacks/Pingbacks