Por Emma Botello
Índice
I. Objetivo
II. Paso 1: Preparación de los datos
III. Paso 2: Generar gráficas para las personas ganadoras de diputaciones
- Gráfica de barras apiladas (por porcentajes)
- Mapa interactivo
- Gráfica de piruleta (lollipop)
IV.Paso 3: Generar gráficas para las personas ganadoras de gubernaturas
- Gráfica de pastel
- Mapa estático del género de ganadores
- Mapa comparando nuevos gobernantes
V. Paso 4: Generar gráfica para las personas ganadoras de presidencias municipales y alcaldías
- Gráfica de barras apiladas (simple)
El 6 de junio de 2021 se celebraron en México las elecciones para diputaciones federales, locales, presidencias municipales y gubernaturas en 15 estados.
Como parte de los proyectos cívicos en el contexto electoral en SocialTIC desarrollamos API CandidaturasMX, que tiene registro de información sobre aproximadamente 3000 candidaturas a diputaciones federales, gubernaturas y presidencias municipales. Para obtener información se pueden hacer peticiones a través de la API, o bien, descargarla en formatos JSON y CSV.
Objetivo
En este tutorial se utilizarán los datos en formato CSV y se generarán visualizaciones con los perfiles de quienes ganaron las candidaturas, tomando en cuenta su estado y género. Estos gráficos permitirán determinar los estados con mayor y menor participación de hombres y mujeres.
¿De dónde obtendremos los datos?
Para este ejercicio obtendremos los datos del repositorio de Github de la API Candidaturas MX. Se recomienda obtener la versión 1.6, en la cual están identificados los y las ganadoras.
¿Qué necesitas?
- Tener instalado R y RStudio
- Tener instaladas las librerías tidyverse, ggplot2, mxmaps, leaflet y scales
- Conocimientos básicos de R, tidyverse y ggplot2
¿Qué aprenderás a hacer?
- Diversas gráficas y mapas. Cómo gráficas apiladas, de paleta y pastel, así como coropletas
- Manipulación de datos
- Unión de data frames
- Reordenamiento de factores
- Personalización de gráficos
- Formatos de datos en R
Para empezar…
Debemos cargar las siguientes librerías: Tidyverse para la manipulación de los datos y ggplot2 con las que se generarán gráficas. El paquete mxmaps, en conjunto con leaflet y scales, permitirán generar mapas estáticos e interactivos.
Paso 1: Preparación de los datos
Se importarán los endpoints en formato .CSV de API CandidaturasMX. De la siguiente manera:

Aquí puedes conocer más información sobre los endpoints (ej. significado de los valores de alguna variable dentro de los endpoints).
Procederemos a unir tablas: person, contest, area, membership y role tomando las variables en común; con la función merge() para generar un data frame que contenga los datos necesarios para generar las visualizaciones que se desean sobre las contiendas electorales de 2021.

Se usará select() para mantener únicamente las variables de interés contenidas en el data frame:

Donde…
-
- gender. Es el género de la persona candidata. Las etiquetas son 1= hombre y 2= mujer.
- state. Es la abreviación del nombre del estado
- city. Contiene el nombre de los municipios (en el caso de presidencias municipales), las alcaldías (en el caso de Ciudad de México) y de las regiones que componen los distritos (en el caso de diputaciones). Los cargos de gubernatura no tienen datos registrados en esta variable.
- membership_type. Indica si la persona ganó la elección (1) o únicamente contendió en la campaña política (2)
- title.y. Contiene el nombre del cargo al que la persona candidata contendió.
Para facilitar la interpretación de las visualizaciones, se asignará el nombre (H y M de hombre y mujer) a las etiquetas de la variable gender: y dado que únicamente se desea mantener los datos de las personas ganadoras, es necesario filtrar los datos:
![]()
![]()
Paso 2: Generar gráficas para las personas ganadoras de diputaciones
Para cualquier gráfica de diputaciones que se desee hacer con la variable state, se debe contar la cantidad de personas de cada género que ganaron en los 32 estados. Para ello, se generará el objeto dip, donde se mantendrán los datos de la contienda a diputaciones con la función filter(), se agruparán los datos por estado y género con group_by() y se contarán el número de casos con la función n(), la cual se incluirá dentro de summarise() asignada a un objeto (puede recibir cualquier nombre, en este caso el objeto también fue llamado n).

-
Gráfica de barras apiladas (por porcentajes)
Se usará la librería ggplot2 para crear una gráfica de barras con características personalizadas.
- Se inicia el plot con la función ggplot(), definiendo las variables que se emplearán para los elementos estéticos en cada eje (state y n en los ejes “x” y “y”, respectivamente), así como la variable que se usará para colorear las figuras (gender).
- Se agrega una capa con la figura de las barras con geom_bar(), indicando que se grafiquen los porcentajes de cada subgrupo con el argumento position=fill, ajustando además el ancho y la transparencia de la figura. Con el resto de las funciones, se modifican detalles estéticos.
- Con scale_fill_manual(), se definen manualmente colores para las etiquetas de gender (H y M). La función coord_flip() cambia los ejes, de tal forma que el eje “x” sea vertical y el eje “y” horizontal. Empleando labs() se define el texto que aparecerá en el título de la gráfica, el título de la escala de colores, el nombre del eje x y el nombre del eje y. Se cambia la apariencia de las líneas de fondo y de los ejes con theme_light(), además se ajusta de manera personalizada el tamaño, color y estilo de diversos elementos de texto con theme().
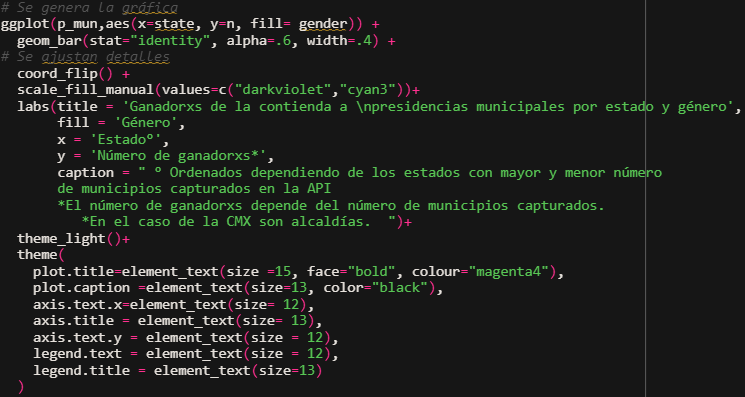
Por último debemos organizar la gráfica de mayor a menor, para hacer que sea más fácil de interpretar. Para conseguir esto, se acomodan manualmente las etiquetas de la variable state.
Para reacomodar las etiquetas, se ejecuta el siguiente código antes de generar el gráfico:

Se reacomodaron las etiquetas de menor a mayor basándose en los porcentajes, ordenando al final aquellas que tenían porcentajes más altos de hombres (ej. San Luis Potosí y Coahuila) y al inicio las etiquetas con mayor porcentaje de diputadas (ej. Chihuahua e Hidalgo). Tras haber redefinido el orden, se obtiene una visualización que podría interpretarse más fácilmente:
Con los mismos datos del data frame dip se pueden generar mapas de coropletas, en los cuales se representan valores de una variable dentro de áreas geográficas a través del llenado de la superficie de las regiones con distintos colores.
La librería mxmaps permite generar tanto mapas estáticos como interactivos apoyándose de otras paqueterías.
-
Mapa interactivo
Se hará un mapa de coropletas a nivel estatal. Para esto, mxmaps requiere que nuestro data frame contenga al menos dos columnas que siempre sean nombradas region y value.
Mxmaps cuenta con data frames que ya contienen alguna información homologada con instituciones nacionales; en esta ocasión usaremos el que se llama df_mxstate_2020.
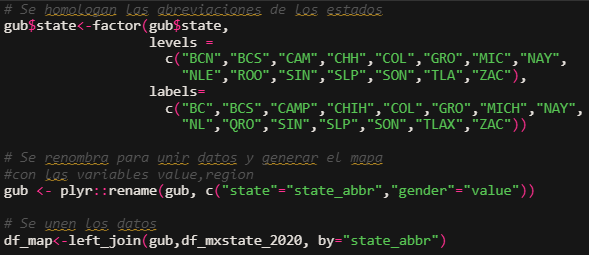
En primer lugar es necesario homologar las etiquetas que indican la abreviación del estado usando la función factor(), poniendo en levels los nombres originales de las etiquetas y en labels los nuevos nombres. Es importante que tanto en levels cómo labels se pongan las etiquetas en el mismo orden.
Una vez ejecutadas estas instrucciones, ambos data frame tienen las mismas abreviaciones para referirse a los estados, lo que permitirá incluir la información de df_mxstate_2020 de manera sencilla.
Ahora tenemos dos valores por estado: número de hombres ganadores y número de mujeres ganadoras de la contienda a diputaciones. Para atender estos casos, se cambiará el formato de nuestro data frame y se calculará la razón entre el número de hombres y mujeres.
Para entender el cambio de formato, es necesario saber que existen el formato largo (long) y el formato ancho (wide). El data frame dip se encuentra en formato long, pues existe una observación (fila) por cada atributo (hombre y mujer). En el formato wide, múltiples atributos se encuentran dispersos en varias columnas, para dip esto implicaría tener una columna para hombres y una para mujeres, cuya intersección con la variable state contendría el número de personas ganadoras tal como se muestra en la siguiente imagen:

Tener nuestros datos en formato wide facilita la inclusión de df_mxstate_2020. Para cambiar el formato wide se emplea la función pivot_wider() de la paquetería tidyr, indicando que se tomen los nombres de las columnas de los valores en la variable gender y los valores para las celdas de la variable n.
![]()
Teniendo los datos en formato wide, también se facilita el cálculo de la razón entre el número de hombres y mujeres, calculada a partir de la división del número de hombres sobre el número de mujeres usando la función mutate().

Ahora, se añadirá la información de df_mxstate_2020. Primero, se cambia el nombre de la variable state de dip_wide a df_mxstate_2020. Hecho esto, se unen los datos con left_join().
Cabe destacar que los datos de la versión 1.6 de API CandidaturasMX contiene valores nulos (NA) y se debe omitir la fila 33.
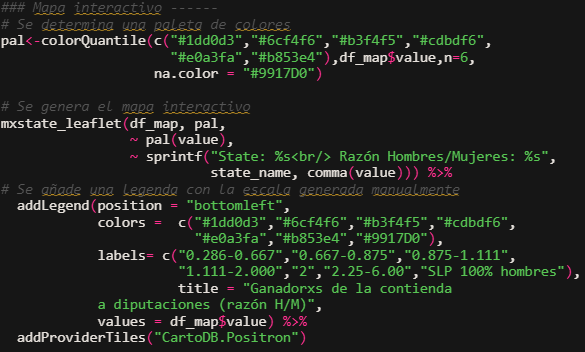
Antes es necesario definir la paleta de colores que se usará para rellenar las figuras de los estados. Para esto vamos a emplear colorQuantile() para construir manualmente una escala de colores. Dentro de la función c() se enlistan los códigos hexadecimales de 6 colores de la paleta personalizada, adicionalmente se define el color que deben tomar los valores nulos (para estos datos, es el color de SLP).
Una vez definida la paleta, se crea el mapa con la función mxstate_leaflet(). Por su parte, sprintf() sirve para mostrar con un pop up el nombre de cualquier estado.
Se añade en la parte inferior izquierda una leyenda con la escala previamente determinada en la paleta de colores, identificando cada color con las etiquetas que se muestran en el mapa estático, se añade además un título para identificar la escala. Finalmente, se añade a CARTO como el proveedor del mapa.
-
Gráfica de piruleta (lollipop)
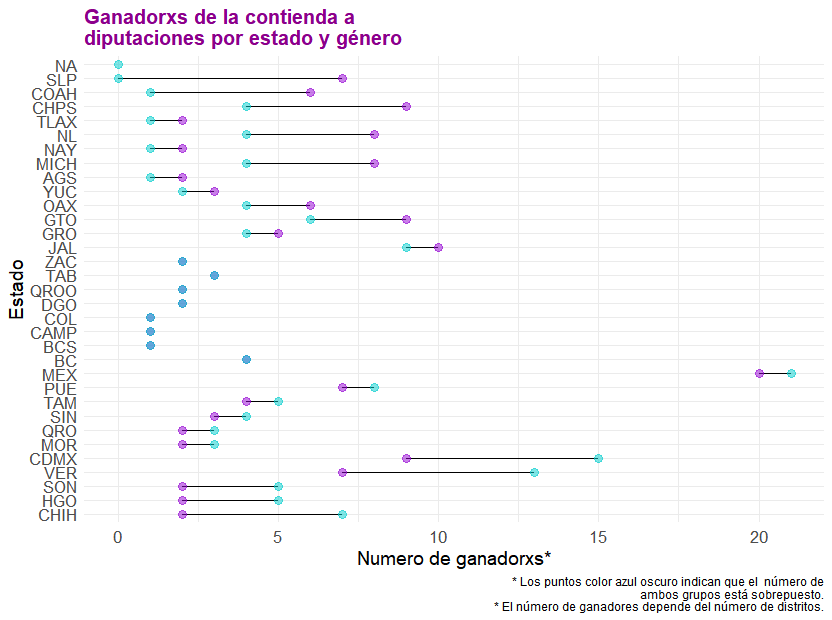
Con esta clase de gráfico es posible notar las diferencias entre dos grupos, pues se muestran los valores de cada grupo con un punto y se les relaciona con una línea cuyo tamaño representa la diferencia.
Tomando esto en cuenta, recordemos que SLP tiene valor nulo en los datos correspondientes a mujeres:
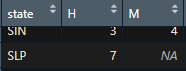
Debido a esto, para poder graficar la diferencia entre el número de mujeres y número de hombres que ganaron la contienda a diputaciones, se reemplaza este valor con 0 de la siguiente forma:
![]()
Una vez hecho esto, se sigue un proceso muy similar al que se ocupa para generar la gráfica de barras apiladas. Las diferencias más marcadas entre los códigos para ambas gráficas son:
- El plot se inicia sin definir los datos empleados para los elementos estéticos.
- Se usan 3 geometrías, las cuales son 2 puntos y una línea/segmento para unirlos.
- Los datos de los elementos estéticos se definen dentro de cada geometría, junto con modificaciones de color y tamaño.

Al ejecutar el código se obtiene esta gráfica:
Paso 3: Generar gráficas para las personas ganadoras de gubernaturas
Al trabajar con los datos de las 15 gubernaturas que se eligieron en las elecciones de 2021. Para fines de la visualización, se agruparán los datos de gubernaturas por estado y género para contarlos y tener una variable numérica que se pueda graficar.
-
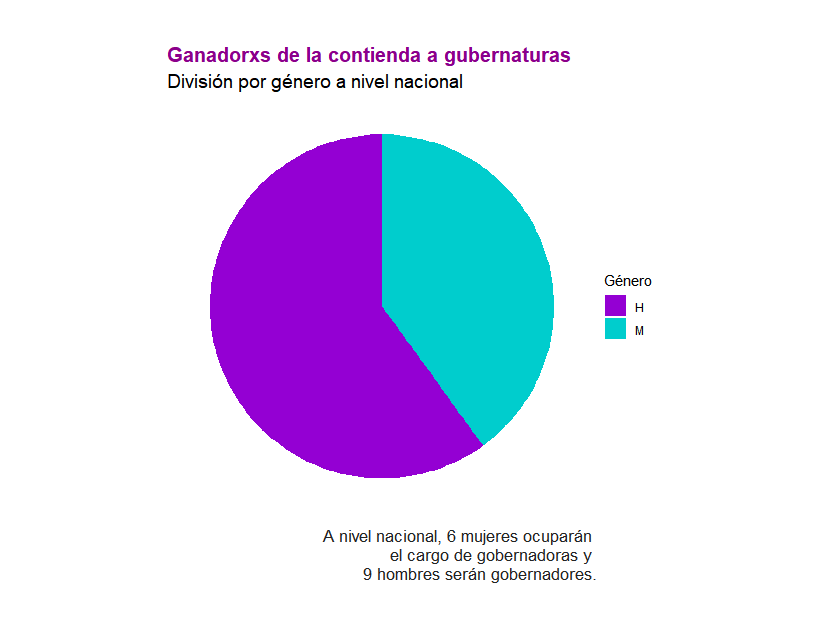
Gráfica de pastel
Para generar una gráfica de pastel es necesario hacer primero una gráfica de barras apiladas.
Al momento de ajustar detalles estéticos, se dan instrucciones adicionales con coord_polar() para convertirla en una gráfica de pastel. Cabe destacar que al momento de definir los datos que se deben emplear para los elementos estéticos dentro de ggplot(), la coordenada x debe quedar vacía. El resto de los elementos añadidos son iguales a los explicados para la gráfica de barras apiladas.
Al ejecutar el código la gráfica queda así:
-
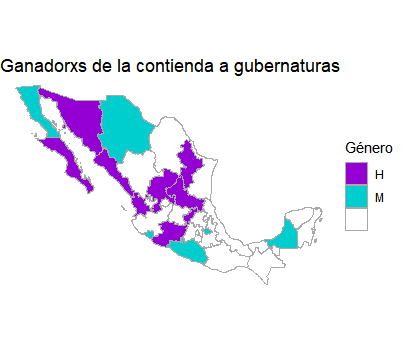
Mapa estático del género de ganadores
Para gubernaturas se harán dos mapas de coropletas. En este caso sólo se homologan las abreviaciones de los nombres de los 15 estados que eligieron personas para gubernaturas y posteriormente se unen estos datos con df_mxstate_2020 para obtener la columna region. En este caso, la columna value será la variable categórica gender.
Para generar el mapa se especifica con scale_fill_manual()los colores asignados automáticamente y se asigna título a la escala, así como nombre a las etiquetas (donde se deja vacío el nombre para los valores ausentes o NA).

El mapa que se obtiene es el siguiente:
-
Mapa comparando nuevos gobernantes
Para el segundo mapa de coropletas, se añadirá manualmente información nueva sobre el género de las personas que ocupaban el cargo de gubernatura en la administración anterior. Esta información no viene incluida en los datos descargados de API CandidaturasMX o en los data frames de mxmaps.
Para capturar esta información, tomamos el data frame df_map e introduciremos el género de las personas que ocupaban el cargo. Los valores deben escribirse en el mismo orden que se encuentran los estados listados en df_map.

Una vez más se generará una nueva variable, la cual será el resultado de la comparación del género de la persona en la administración anterior con el género de la persona que ganó la contienda en 2021.

Como podemos observar, se obtiene el valor lógico FALSE cuando el género de la persona que ocupaba el cargo es diferente al género de la persona que ganó en las elecciones. Mientras que el valor TRUE indica que el género de ambas personas es el mismo.
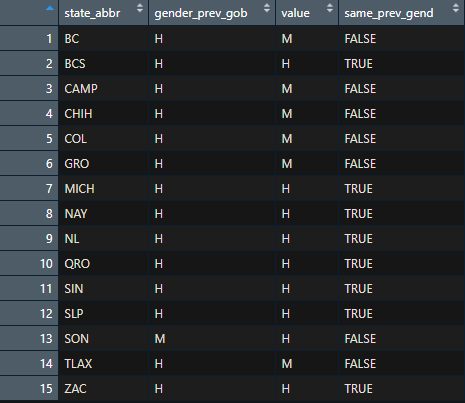
Para generar el mapa de coropletas, es necesario renombrar las columnas para que se reconozca a same_prev_gender como la variable a graficar. Se hace esto con la función rename().

Dado que la columna que vamos a graficar contiene elementos de clase logical, debe forzarse a esta variable a comportarse como factor, de lo contrario no podría generarse el gráfico.
![]()
Una vez hecho esto, se siguen los siguientes pasos, obteniendo el siguiente resultado.

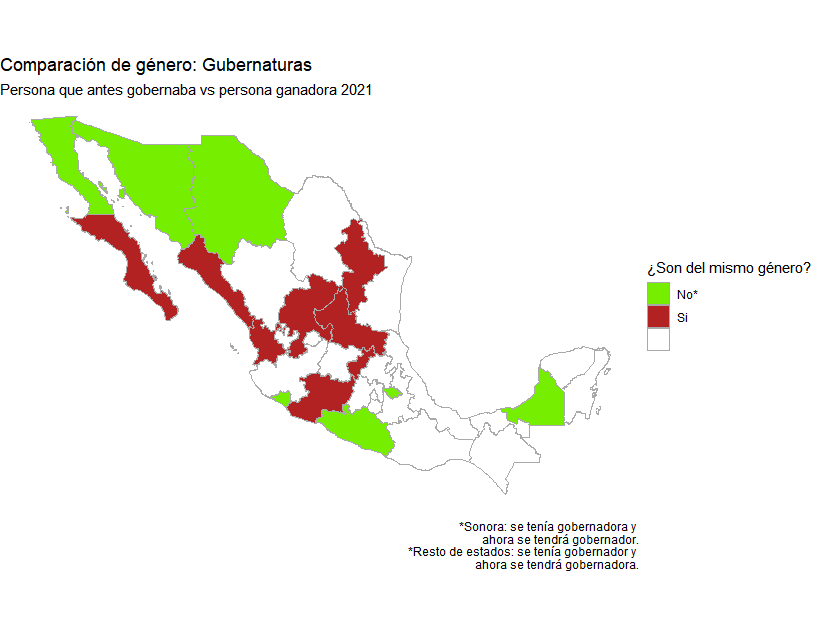
Paso 4: Generar gráfica para las personas ganadoras de presidencias municipales y alcaldías
Para el caso de presidencias municipales, el equipo de SocialTIC capturó los datos de algunos municipios existentes en los diversos estados. Por ello, representaremos los datos mediante una gráfica de barras apiladas simple, donde sea posible observar las diferencias del número de personas ganadoras que se tienen registradas en los datos de API CandidaturasMX.
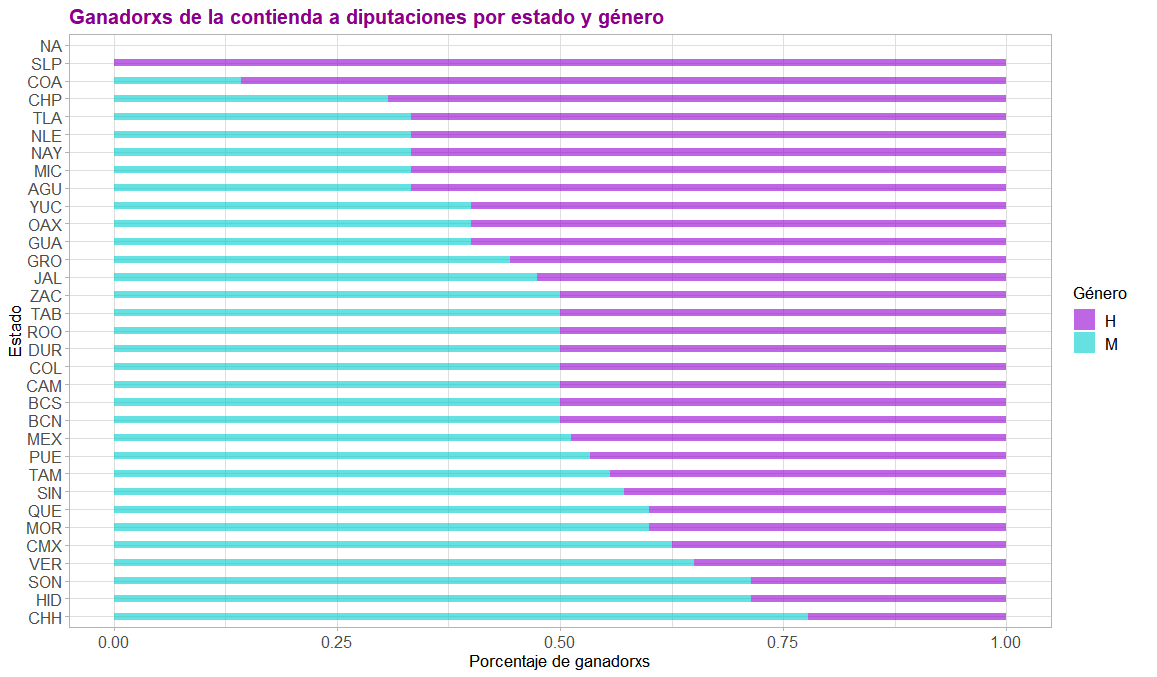
Primero, al igual que con las otras contiendas, se filtran los datos de las personas ganadoras para mantener únicamente los de presidencias municipales y alcaldías (ambos casos etiquetados como Mayor), posteriormente se agrupan y se cuentan.

-
Gráfica de barras apiladas (simple)
Al igual que en el caso de la gráfica de barras apiladas por porcentajes, los datos de las variables que se emplearán para los elementos estéticos son definidos al generar el plot. En este caso, dentro de geom_bar() no se incluye un argumento “position”.
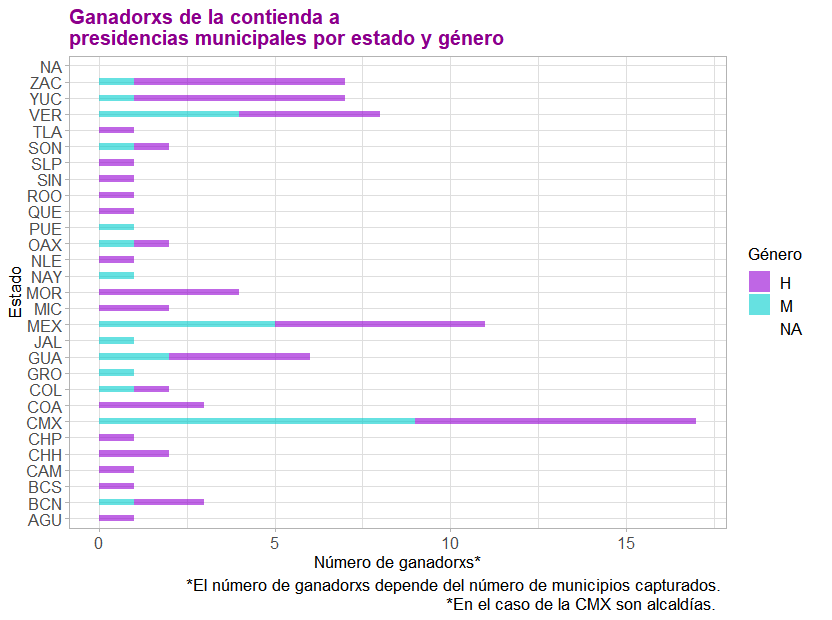
Nuevamente, notamos que la visualización podría mejorar al ser ordenada, por lo cual se identificará a los municipios con mayor y menor número de municipios capturados en la API. Es importante entender que no son los estados que tienen mayor y menor número de municipios. Pueden existir estados con un alto número de municipios, pero al no estar capturados en los datos esto no se refleja en la visualización. Se ordenan las etiquetas de los estados manualmente:

Y se añade una nota a la gráfica para clarificar el criterio con el cual fueron ordenados los estados:

¡Y listo! Ahora sabes cómo generar diversos tipos de gráficas personalizadas relacionadas a género. 👍