
Por Frida García Celis
¿Qué necesitas?
- Un dataset que contenga texto. Por ejemplo, un conjunto de tweets o notas de periódicos.
- Tener instalado R y RStudio.
- Conocimientos básicos de RStudio y tidyverse.
Conceptos básicos
- Token. Se refiere a la observación almacenada en una fila, a menudo es una sola palabra, pero también pueden ser n-gramas, oraciones completas o hasta párrafos.
- Tokenización. Es la función requerida para convertir un texto completo en un token, es decir, en elementos más pequeños.
- String. O cadena de texto, por ejemplo, vectores de caracteres que en conjunto forman palabras, oraciones, o párrafos, es decir, la forma en la que se almacenan textos.
- Stopwords. Son palabras que usamos comúnmente para comunicarnos y nos sirven para dar contexto y entendernos, por ejemplo, preposiciones o artículos. En análisis de texto se eliminan pues no aportan información.
- Vector. Un vector es una colección de uno o más datos del mismo tipo. Si tenemos un vector de tipo “caracter” todos los elementos serán caracteres, es decir, no se pueden combinar.
¡Comencemos!
El análisis de texto es un proceso de fragmentación de párrafos o comunicaciones escritas, en oraciones y en palabras, a partir de un separador definido, por ejemplo, un espacio. Con el fin de medir frecuencias de palabras, relaciones entre ellas o los sentimientos que evocan cada palabra.
En esta entrada te llevaremos paso a paso para realizar tu propio análisis tomando como base el análisis de publicaciones de facebook en torno al 8m, utilizando RStudio.
Es prioritario tener claridad antes de comenzar el análisis de texto, por eso te recomendamos lo siguiente:
- Define el problema u objetivo a resolver
- Identifica el texto a utilizar en la resolución del problema
- Organiza el texto
- Extrae características
- Analiza los resultados para obtener respuestas al problema planteado
Hay diferentes formas de extraer texto, desde paquetes que contienen capítulos enteros de diferentes libros, scrapeando páginas de internet o bien accediendo a publicaciones de redes sociales a través de sus APIs. Para efectos de este tutorial se usaron los datos de los posts que se hicieron en FB y que obtuvimos utilizando CrowdTangle.
Antes que nada, debemos hablar a las siguientes librerías para nuestro análisis. El paquete tidyverse, famoso ya, nos servirá para escribir código de forma sencilla, por su parte, los paquetes tm y tidytext son propios para el análisis de texto.

Después se importará el archivo que contenga el texto que se va analizar. En este caso, importamos la publicaciones hechas en Facebook que incluían #8M y #DíaDeLaMujer, o ambos, y lo guardaremos en un objeto llamado data. Acto seguido usaremos la función select() para elegir, por posición, las columnas con las que vamos a trabajar, y colnames() para saber el nombre de las columnas seleccionadas. Este subconjunto lo almacenaremos en el objeto tempo.
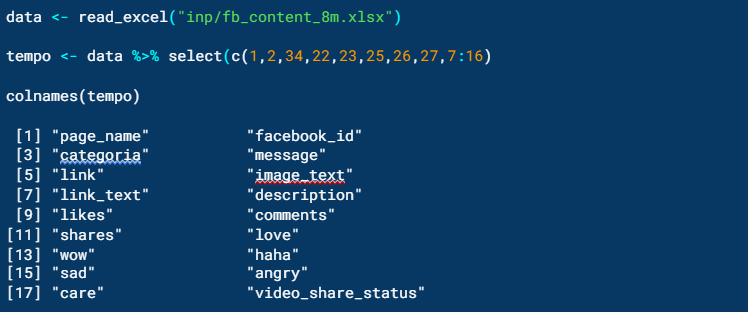
La descripción de las variables son:
- Page_name es el nombre de la página
- Facebook_id se refiere al identificador de cada página
- Categoría es la clasificación de cada una de las páginas. La categorización se hizo previo iniciar el análisis consultando los perfiles de Facebook.
- Message es el texto de cada publicación
- Link es el URL que redirecciona a cada publicación
- Image_text, link_text contiene información de aquellas publicaciones con imágenes
- Likes, comments, shakes, love, wow, haha, sad, angry, care, contabiliza el número de reacciones que tuvo cada publicación
Siguiendo con la exploración de datos, utilizamos nrow() para saber el total de publicaciones en tempo y table() para saber cuántas categorías hay. El resultado es que hay 907 publicaciones en total y 10 tipos de perfiles diferentes.
Con la función table() podemos saber cuántas publicaciones hay por cada categoría y el número de publicaciones por cada una.
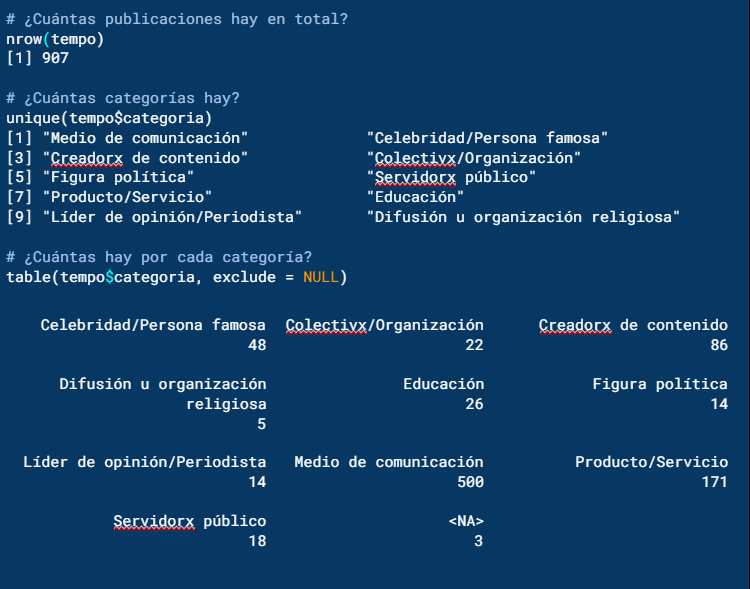
Como se muestra arriba en las categorías de los perfiles: medio de comunicación, producto/servicio y creadorx de contenido son las tres que más publicaciones tienen.
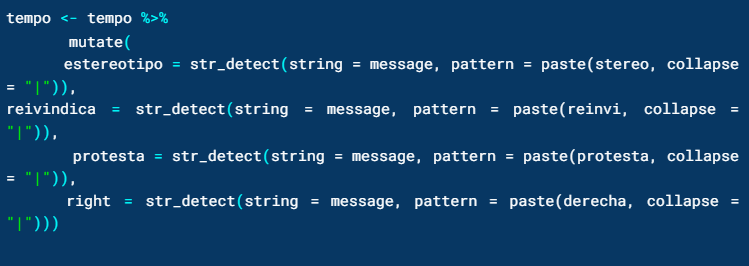
Después crearemos cuatro vectores de palabras que estén asociadas semánticamente a los siguientes conceptos: estereotipos, reivindicación, protesta y antiderechos. A continuación puedes leer las palabras que incluimos en cada uno de estos vectores.

Para saber la temática de cada mensaje, según las palabras que incluye, crearemos cuatro diferentes variables, una por cada concepto. El resultado será un dato lógico o booleano, es decir, TRUE o FALSE.
De tal manera que, usaremos la función mutate para crear las variables con base en las coincidencias que estipulamos con la función str_detect. Dicha función requiere un vector, en este caso la variable message, y un patrón, que serán los cuatro conjuntos de palabras arriba descritos.
Ya que es un listado de palabras y se busca la coincidencia con al menos una de ellas, usaremos collapse para separarlas usando el operador lógico OR “|”.
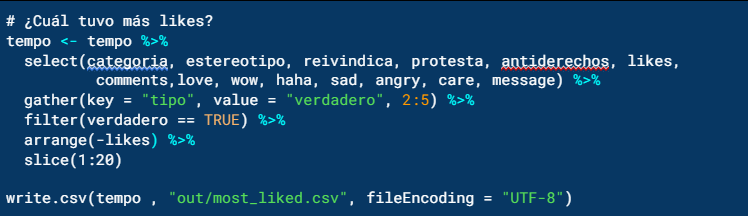
Por último para saber qué tipo publicación tuvo más me gusta, ejecutaremos las siguientes líneas:
- Seleccionar variables
- Reordenar de tabla
- Filtrar valores verdaderos
- Ordenar
- Conservar las 20 con más likes
- Exportar tabla
Y así, con un código fácil puedes hacer un análisis de texto con R.